
무엇을 캐싱했을까?
보고 또 보고 에서는 문제집 검색 기능을 제공한다.
검색 기능이 고도화되면서 키워드로 검색된 문제집 결과에 유저, 태그로 필터해주는 기능도 추가되었다.
이렇게만 들었을 때는 '검색된 문제집들의 유저와 태그 리스트가 있을테니 이를 사용하면 되겠다!' 싶겠지만 그렇게 간단하지만은 않았다.
그 이유는 페이징 처리때문이었다.
문제집 검색은 문제집 이름 중 키워드가 포함되어 있는 문제집 20개씩 페이징 처리를 해서 보여준다.
하지만 필터를 위해서 필요한 태그와 유저 리스트는 키워드에 해당하는 문제집 전체의 태그와 유저 리스트였다.
즉, 필요한 유저와 태그 리스트는 페이징 처리로 인해 매번 데이터를 추가해야 하는 것이 아닌 고정되어 있어야 했다.
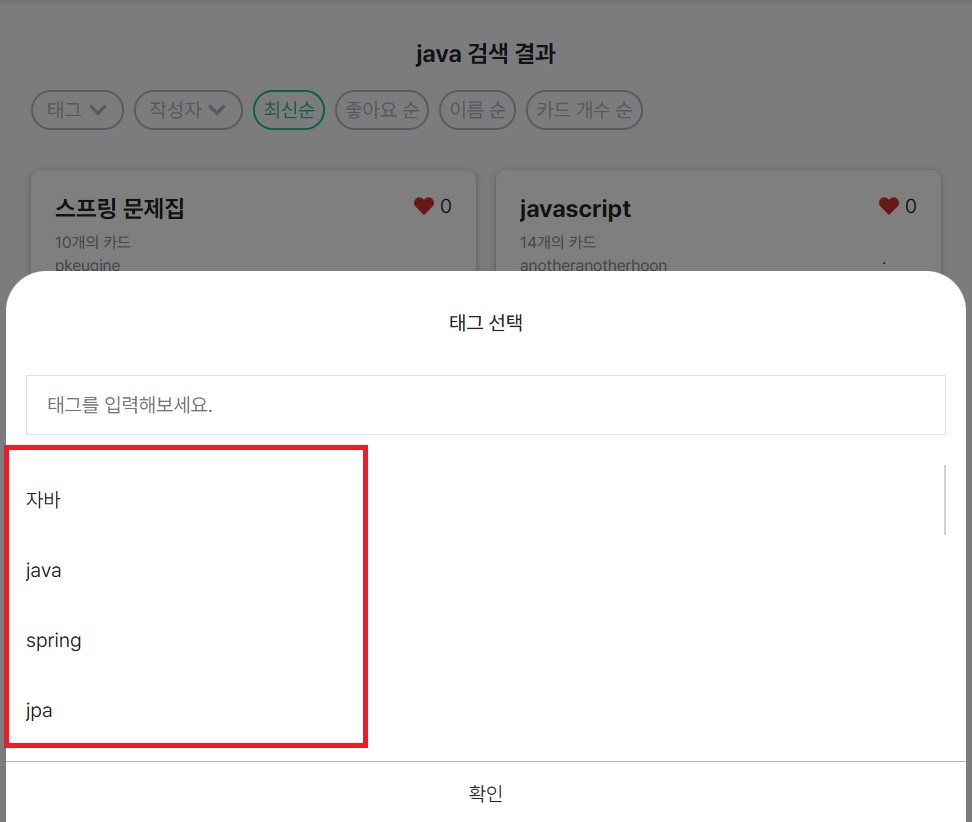
그렇게 하기 위해서 결국 우리가 생각했던 방식은 새롭게 유저 및 태그 리스트를 불러오는 api를 만들고 이를 이용하는 것이었다.
마음에 들지 않았지만 현재 상황에서는 이 방법이 최선이라고 생각했고 결과적으로 해당 기능은 무사히 구현하게 되었다.
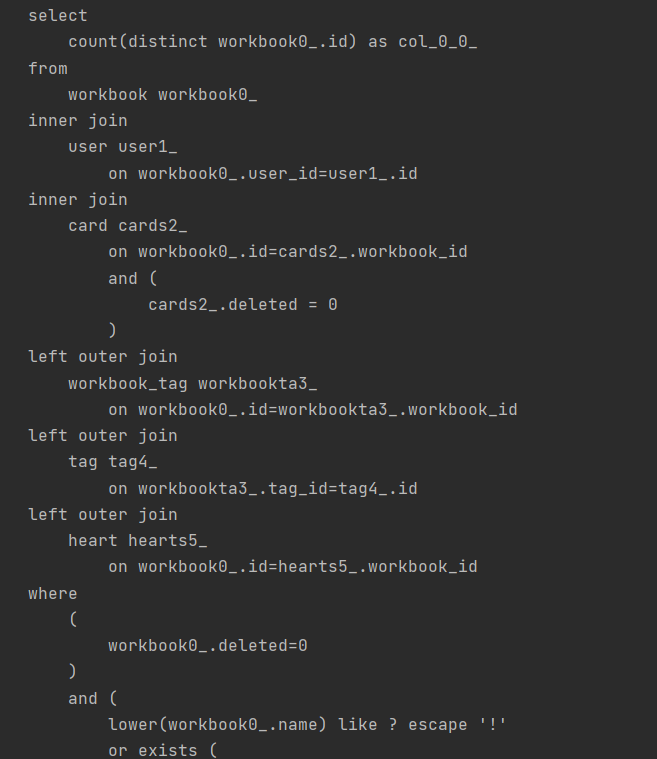
하지만 문제는 매번 검색을 할 때마다 키워드에 해당하는 문제집 리스트만 I/O 작업을 통해 DB에서 들고 오는 것이 아니라 유저와 태그 리스트도 DB에서 들고와야 했다.
즉, 문제집 조회 기능을 위해서 매번 유저, 태그 리스트 조회를 위해 쿼리가 추가적으로 나가야 했다.
- 문제집 조회 쿼리
- 태그 조회 쿼리
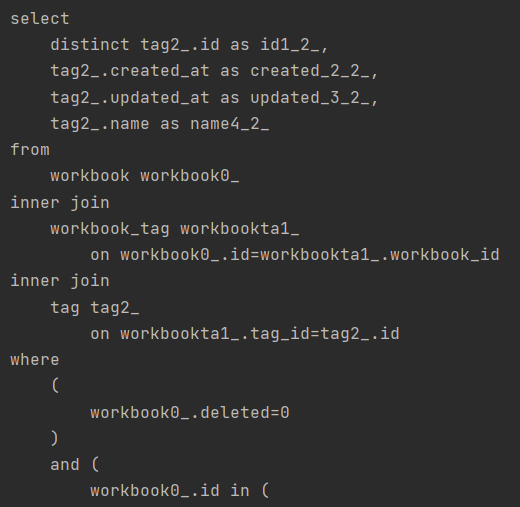
동일한 키워드를 계속해서 검색할 때마다 유저, 태그 리스트를 조회하는 쿼리가 나가는 것은 매번 I/O 작업을 하는 것이라 속도가 느리고 성능상 좋지 않을 것이라고 판단했고 이를 위해 캐싱을 적용해야겠다고 생각하게 되었다.
그리고 때마침 인기 검색어와 인기 문제집을 위해서 Redis를 사용하고 있었고 WAS별로 캐시 공유 및 TTL 설정을 위해 저장소로 Redis를 사용하기로 했다!
-
그렇다면 Memcached는?
- 캐싱을 위한 저장소로 Memcached도 있는 것으로 알고 있다.
- 두 개 다 메모리에 데이터를 저장하여 캐싱 기능으로 사용하기 좋고 편리하다고 할 수 있지만 팀에서 이미 '인기 검색어'와 '인기 문제집' 기능을 위해 Redis를 사용하고 있었다
- 특히, 인기 검색어는 sorted set이라는 자료구조를 활용하여 랭킹 처리를 하고 있었기에 Redis 사용이 확실했다.
- 정리하자면 Redis에서 제공해주는 다양한 자료구조, 기존에 사용하던 Redis를 그대로 사용함으로써 관리 포인트를 줄이기 위해 Redis를 사용했다고 볼 수 있다. (물론 문서가 다양하다는 장점도 있다ㅎㅎ)
왜 캐싱을 하면 빠를까?
왜 캐싱을 하면 빠를까?
조금 더 구체적으로 말하면 '왜 In-Memory가 Disk I/O보다 빠를까?'라고 말할 수 있다.
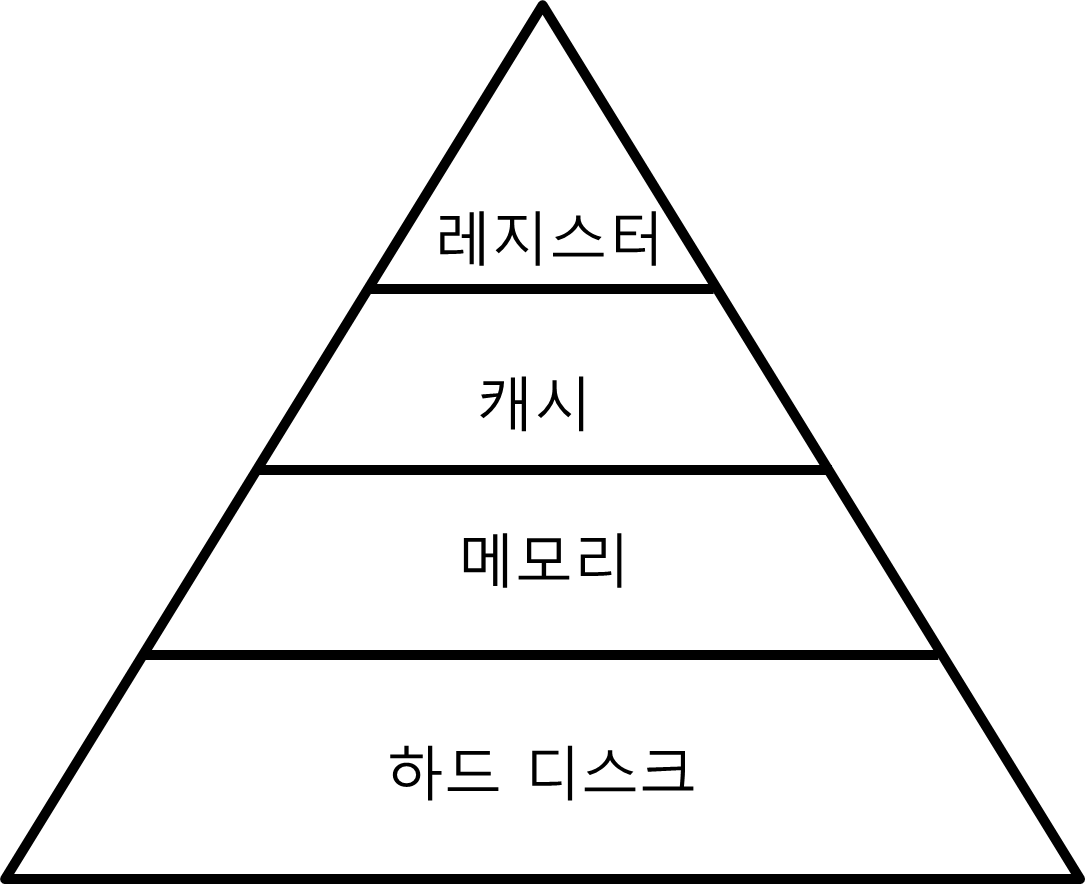
메모리 계층 구조를 보게 되면 위에서 아래로 갈수록 CPU 접근 속도가 느려진다.
CPU는 레지스터, 캐시, 메인 메모리는 직접적인 접근이 가능하나 하드 디스크의 경우 직접 접근할 방법이 없다.
그래서 하드 디스크의 데이터를 메모리로 이동시키고, 메모리에서 접근해야 한다.
그러다보니 당연히 메인 메모리에 데이터를 저장하는 In-Memory DB가 하드 디스크에 저장하는 Disk-Based DB보다 빠른 것이다.
캐싱 전략 및 적용해보기
캐싱 전략으로 두 가지 정도 짚고 넘어볼 수 있다.
1) Look Aside (= Lazy Loading)
이름 그대로 캐시를 옆에 두고 필요할 때만 데이터를 캐시에 로드하는 캐싱 전략이다. 캐시는 데이터베이스와 애플리케이션 사이에 위치하여 단순 key-value 형태를 저장한다. 애플리케이션에서 데이터를 가져올 때 Redis에 항상 먼저 요청하고, 데이터가 캐시에 있을 때에는 Redis에서 데이터를 반환한다. 만약 데이터가 캐시에 없을 경우 데이터베이스에 데이터를 요청하고, 애플리케이션은 이 데이터를 다시 Redis에 저장한다.
-
장점
- 실제로 사용되는 데이터만 캐시할 수 있다.
- Redis의 장애가 애플리케이션에 치명적인 영향을 주지 않는다.
-
단점
- 캐시에 없는 데이터를 조회할 때는 캐시에서 데이터에 대한 초기 요청, 데이터베이스 쿼리, 캐시에 데이터 쓰기와 같은 과정이 발생해 오랜 시간이 걸릴 수 있다.
-
캐시가 최신 데이터를 가지고 있다는 것을 보장하지 못한다. 데이터베이스에서 데이터가 변경될 때 캐시에 대한 업데이트가 없기 때문에 발생한다.
- Write Through 전략을 택하거나 TTL(Time To Live) 설정을 통해 해결할 수 있다.
2) Write Through
데이터베이스에 데이터를 작성할 때마다 캐시에 데이터를 추가하거나 업데이트한다.
-
장점
- 캐시의 데이터는 항상 최신 상태로 유지할 수 있다.
-
단점
- 데이터 입력시 두번의 과정을 거쳐야 하기 때문에 지연 시간이 증가한다.
-
사용되지 않을 수도 있는 데이터도 일단 캐시에 저장하기 때문에 리소스 낭비가 발생한다.
- TTL 설정으로 해결할 수 있다.
보또보에서는?
캐싱에 사용되는 key는 검색 키워드고 value는 태그 리스트였다.
당시에는 이정도까지 전략에 대해 깊은 고민을 하지 않았다. (용어도 잘 몰랐다)
그렇기에 검색할 때 캐시 데이터가 존재하면 그 데이터를 반환하고 아니면 새로 DB에서 조회하고 캐싱하면 되겠다 싶어서 Look Aside 전략을 택했다.
최신 데이터가 아닌 점은 해당 데이터가 짧은 시간동안 정합성이 어긋나도 사용자 입장에서 서비스를 이용하는데 크게 영향을 끼칠 데이터가 아니므로 괜찮다고 생각했기에 TTL 설정을 통해 해결하고자 했다.
TTL의 경우 현재 10분으로 설정되어 있지만... 아무리 캐싱으로 성능을 높이고 태그라는 데이터가 미치는 영향이 엄청 크지 않다고 해도 10분간 데이터 정합성이 어긋나는건 조금 아닌거 같다는 생각이 든다.
추후에 변경을 해야겠다.
적용 코드
본 코드는 프로젝트에서 사용한 코드 일부를 가져온 것이다.
필자가 구현한 부분은 Redis를 사용한 캐싱이었으므로 코드 또한 캐싱 관련 설정 및 구현 코드다.
이외에도 RedisTemplate, StringRedisTemplate 등을 사용하여 다른 팀원들이 구현한 리프레시 토큰을 저장한다던가 랭킹 기능 부분도 존재하지만 그 부분은 추후에 다뤄보겠다.
dependencies {
// Redis
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-cache'
}Cache를 사용하고 저장소로 Redis를 사용하기 위해 위와 같은 의존성을 추가했다.
spring:
redis:
host: redis 서버 ip 주소
port: 6379 # redis 기본포트는 6379다@Configuration
public class RedisConfig {
private final RedisProperties redisProperties;
public RedisConfig(RedisProperties redisProperties) {
this.redisProperties = redisProperties;
}
// 1
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration redisStandaloneConfiguration = new RedisStandaloneConfiguration();
redisStandaloneConfiguration.setHostName(redisProperties.getHost());
redisStandaloneConfiguration.setPort(redisProperties.getPort());
return new LettuceConnectionFactory(redisStandaloneConfiguration);
}
}Redis 설정 클래스와 Cache 설정 클래스를 따로 나누었다.
- yml에 설정한 Redis 정보를 이용해 RedisConnectionFactory 인터페이스 구현체를 만들어서 반환한다.
RedisConnectionFactory는 Redis에 접근을 도와주는 인터페이스로 구체적으로 Redis 연결에 사용되는 RedisConnection을 생성한다.
이때 구현체인 Client로 Java는 크게 Jedis, Lettuce 크게 2가지를 지원해준다.
2개 중에 Lettuce를 택하게 되었는데 그 이유는
Lettuce는 Netty 기반 Reids Client로 비동기 방식으로 요청을 처리해주므로 성능이 좋고 무엇보다 Spring-data-redis에서 제공해주는 기본 Client이므로 따로 의존성을 추가할 필요가 없기 때문에 간편하게 사용할 수 있기 때문이다.
성능과 관련한 글은 이동욱님의 글 을 참고하길 바란다.
// 1
@Configuration
@EnableCaching
// 2
public class CacheConfig extends CachingConfigurerSupport {
private final RedisConnectionFactory redisConnectionFactory;
public CacheConfig(RedisConnectionFactory redisConnectionFactory) {
this.redisConnectionFactory = redisConnectionFactory;
}
// 3
@Bean
@Override
public CacheManager cacheManager() {
return RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(defaultConfiguration())
.withInitialCacheConfigurations(cacheConfigurations())
.build();
}
// 4
private Map<String, RedisCacheConfiguration> cacheConfigurations() {
return Map.of(
"filterTags", durationConfiguration()
);
}
// 5
private RedisCacheConfiguration defaultConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofDays(7))
.disableCachingNullValues()
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer()
)
);
}
// 6
private RedisCacheConfiguration durationConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(10));
}
}캐싱 설정 관련 클래스다.
- @EnableCaching은 내부적으로 Spring AOP를 이용하여 애노테이션 기반 캐싱 설정을 사용하게 해준다.
- 현재 코드에는 없지만 프로젝트에서 CacheManager를 2개를 빈으로 등록해두고 사용한다.
RedisCacheManager와 ConcurrentMapCacheManager인데 이러한 Multiple CacheManager 사용을 위해서는 @Primary를 사용해 우선적으로 등록을 시켜줄 CacheManager를 정해주거나 CacheConfigurerSupport를 상속하여 구현하면 된다. - 빈으로 등록된 RedisConnectionFactory를 사용하는 RedisCacheManager를 만드는데 이때 cacheDefaults와 withInitialCacheConfigurations를 설정했다.
기본적으로 withInitialCacheConfigurations에서 관리되는 cacheName 인지 먼저 보고 없으면 cacheDefaults를 사용한다고 한다.
참고로 현재 cacheDefaults에 설정된 RedisCacheConfiguration은 리프레시 토큰 관련 설정이다. - cacheName 별로 RedisCacheConfiguration을 가지고 있는 Map을 반환한다. 코드에는 filterTags 밖에 없지만 실제로는 다른 설정도 등록되어 있다.
- 리프레시 토큰 관련 설정으로 TTL은 7일 직렬화 옵션으로 GenericJackson2JsonRedisSerializer를 사용했다.
- 태그 캐시 설정으로 TTL을 10분으로 설정했다.
@Service
@Transactional(readOnly = true)
public class TagService {
private final TagRepository tagRepository;
private final TagSearchRepository tagSearchRepository;
public TagService(TagRepository tagRepository, TagSearchRepository tagSearchRepository) {
this.tagRepository = tagRepository;
this.tagSearchRepository = tagSearchRepository;
}
@Cacheable(value = "filterTags", key = "#filterCriteria.workbook")
public List<TagResponse> findAllTagsByWorkbookName(FilterCriteria filterCriteria) {
String keyword = filterCriteria.getWorkbook();
if (filterCriteria.isEmpty()) {
return TagResponse.listOf(Tags.empty());
}
List<Tag> findTags = tagSearchRepository.findAllByContainsWorkbookName(keyword);
return TagResponse.listOf(Tags.of(findTags));
}
}마지막으로 TagService에서 캐시 애노테이션을 사용한 코드다.
저장하는 key는 검색 키워드, value는 TagResponse List로 설정하였다.
먼저 Redis에 key가 존재하는지 확인하고 존재하면 바로 해당 value를 이용해 응답을 보내주고
존재하지 않으면 DB에 요청을 해서 태그 리스트를 조회하고 TagResponse로 변환한 뒤 응답을 보내주었다.
성능 측정
성능 테스트를 위해 테스트 서버를 구축하고 데이터베이스에 문제집 100만, 태그 만 개 정도를 넣어두고 테스트를 진행해봤다.
하지만, 아쉽게도 쿼리가 문제가 있었는지 데이터가 많을 때는 테스트를 하기 힘들 정도로 조회 속도가 느렸다.
추후에 쿼리 튜닝을 해야겠다는 생각을 하고 일단 개발 서버에 존재하던 데이터로만 테스트를 진행했다.
테스트 도구로 k6를 사용했고 VUSER는 100으로 설정했다.
100으로 설정한 이유는 1명당 1일 평균 요청 수를 피크시간 대에 60~70이라고 잡고 태그 조회 api의 요청 수는 1이고 지연시간이 0.5라고 가정했을 때
(60*1.5)/1 = 90이고 (70*1.5)/1 = 105 니까 어림잡아 100으로 설정하게 되었다.
-
캐싱 전
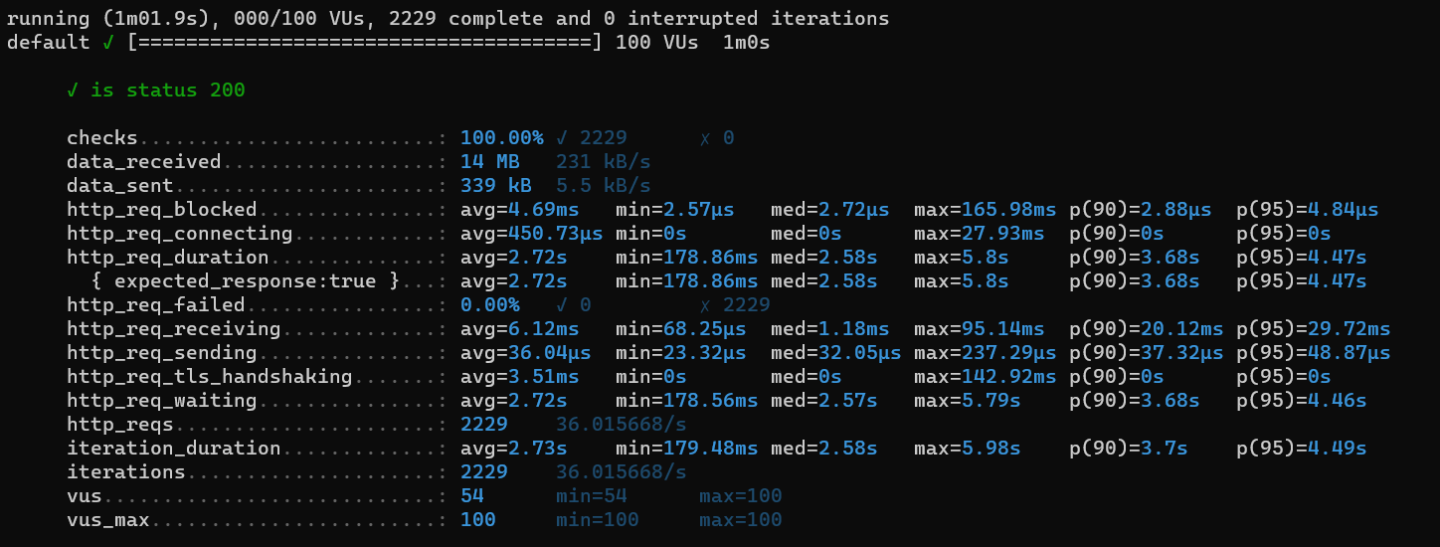
-
캐싱 후
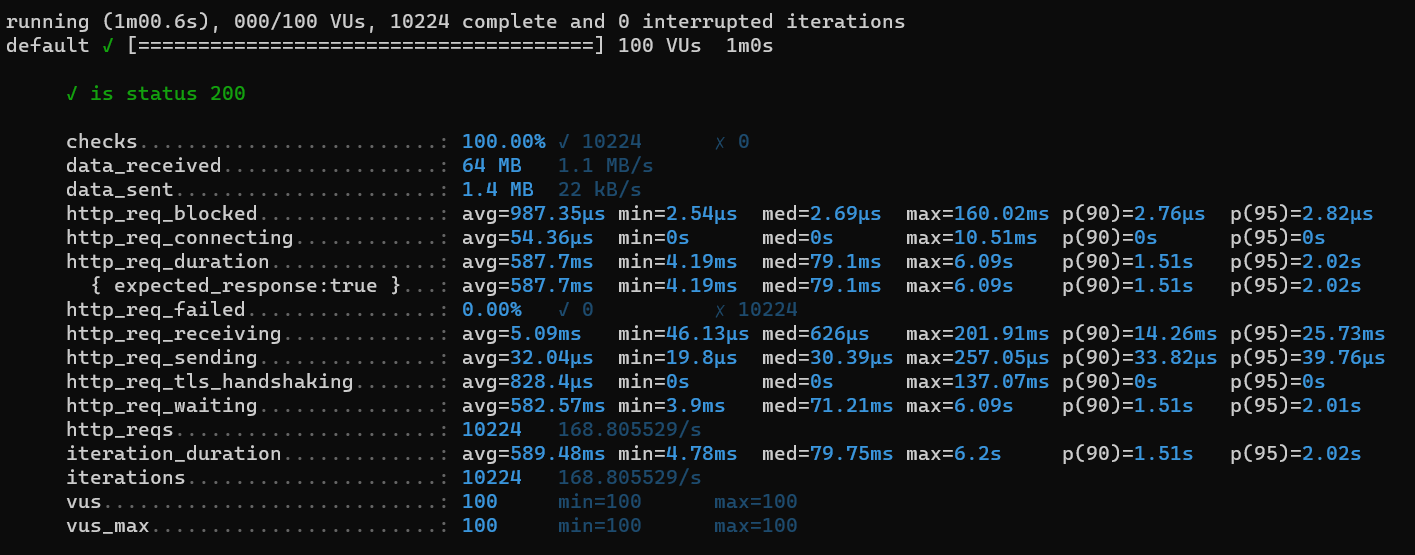
측정 결과 요청 응답 시간이 평균 2.72sec에서 587ms로 줄어든 것을 볼 수 있었다.
아쉬운 점
- 성능테스트를 조금 더 깊게 해볼껄 이라는 아쉬움이 들었다.
앞서 말했듯 대량의 데이터를 이용해 측정을 하지 못했고 단순하게 k6만 돌려놓기만 하고 해당 서버에서 vmstat을 사용해 시스템 모니터링을 하지 못했다.
k6 설정도 조금 아쉬웠다. 테스트 시간을 더 길게 잡고 해봤어야 했는데..
- 다른 크루에게 '왜 검색 결과에 해당하는 문제집 리스트를 캐싱하지 않았어?' 라는 질문을 들었던 적이 있었다.
당시에는 문제집 결과를 캐싱할 생각을 못했다.
아마 api가 여러번 나가게 된다는 것에 초점을 뒀고 문제집은 페이징 처리가 되어있다보니 힘들다고 예상해서 제외를 했던 것 같다.
하지만 지금 생각해보니 페이징 처리가 되어있다고 해도 캐싱은 충분히 해줄 수 있을 것 같았다.
그렇다면 데이터 정합성과 관련해서 캐싱 전략을 세우고 적절한 트레이드 오프를 찾는다면 문제집 결과를 캐싱하는 것이 성능을 더 향상시킬 수 있지 않을까? 라는 생각이 든다.
- 면접에서 받았던 질문으로 '키워드에 해당하는 문제집이 추가가 되었을 때 태그 리스트도 변경이 될 수 있는데 이 부분은 어떻게 생각하냐?' 가 있는데
당시에 'TTL을 1분(인줄 알았는데 10분이었다)으로 설정했고 해당 데이터가 짧은 시간동안 정합성이 어긋나도 사용자 입장에서 서비스를 이용하는데 크게 영향을 끼칠 데이터가 아니므로 괜찮다고 생각한다. 그리고 키워드에 해당하는 문제집이 추가되었을 때 저장되어있던 캐시를 비워주는 방법도 생각하고 있다. 어쩌고 저쩌고~'
이런 느낌으로 대답을 했었는데 돌아온 질문이 '어떻게 문제집을 추가할 때 키워드와 관련된 캐시를 삭제할 수 있냐?' 였고 그럼 캐시 전부를 비우는 방법도 있겠는데 그 부분은 조금 더 생각해봐야겠다고 답변했던 경험이 있다.
끝나고 나서도 지금까지 드는 고민은 어떻게 할 수 있을까? 였다.
결국 트레이드 오프라고 생각하고 받아들여야 하는건가 아님 전략을 바꿔 문제를 해결해야 하는건가 계속 고민 중이다.
마무리
- 캐싱과 Redis에 대해 공부하게 된 좋은 시간이었다.
- 과연 현재 캐싱한 데이터가 정말로 캐싱하기 적합한 데이터였을까? 하고 생각하면 자신있게 대답은 하기 힘들 것 같다. 하지만 당시에는 이 방법이 최선이었다고 생각한다..ㅎㅎ
- 항상 캐싱을 할땐 데이터 정합성을 생각하며 팀 차원에서 적절한 전략을 세우도록 하자.
참고
- https://meetup.toast.com/posts/225
- https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/Strategies.html
- https://ko.wikipedia.org/wiki/메모리_계층_구조
- https://www.baeldung.com/spring-multiple-cache-managers
- https://velog.io/@bonjugi/RedisCacheManager-TTL-Serializer-%EB%A5%BC-%EC%BA%90%EC%8B%9C%EC%9D%B4%EB%A6%84%EB%B3%84%EB%A1%9C-%EB%8B%A4%EB%A5%B4%EA%B2%8C-%EC%84%A4%EC%A0%95%ED%95%98%EA%B8%B0
- https://jojoldu.tistory.com/418
- https://github.com/binghe819/TIL/blob/master/Spring/Redis/spring%EC%9C%BC%EB%A1%9C%20redis%EB%A5%BC%20%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0%20%EC%A0%84%EC%97%90%20%EB%B3%B4%EB%A9%B4%20%EC%A2%8B%EC%9D%80%20%ED%81%B0%20%EA%B7%B8%EB%A6%BC/spring%EC%9C%BC%EB%A1%9C%20redis%EB%A5%BC%20%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0%20%EC%A0%84%EC%97%90%20%EB%B3%B4%EB%A9%B4%20%EC%A2%8B%EC%9D%80%20%ED%81%B0%20%EA%B7%B8%EB%A6%BC.md