
Master & Slave DB 설치
sudo apt update
sudo apt install mariadb-serverMaster DB 설정
CREATE DATABASE db_name DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;//user 생성
//% 로 설정하면 외부에서도 접근 가능
create user 'username'@'%' identified by 'password';//해당 계정에 전체 권한이 열림
grant all privileges on {database}.* to 'username'@'%';
flush privileges;
//replication에 대한 권한만 설정하려면 이렇게
//위와 같이 {database}.*를 하면 예외가 발생함
//ERROR 1221 (HY000): Incorrect usage of DB GRANT and GLOBAL PRIVILEGES
grant replication slave on *.* to 'username'@'%';
flush privileges;- 아래 파일에서 설정 수정

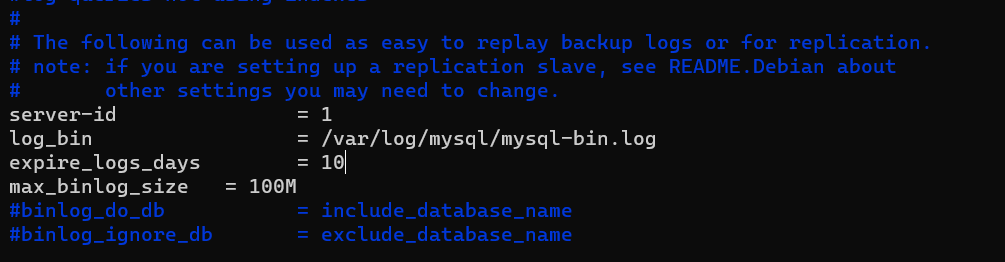
- mariadb 재시작
sudo service mysqld restart- master db의 File과 Position 값을 slave db에 설정해야함

- File은 replica(slave db)가 master db의 데이터를 읽을 binary 파일이고 Position은 읽기 시작할 위치를 뜻함.
- 즉 slave에서 File과 Position을 설정하면 master의 어떤 파일의 어떤 위치부터 읽겠다는 뜻. 보통 비동기 방식으로 이 파일을 읽어 slave에서 반영한다.
Slave DB 설정
- 같은 계정을 만들어주고 권한도 주어야한다.
//user 생성
//% 로 설정하면 외부에서도 접근 가능
create user 'username'@'%' identified by 'password';- master db와 마찬가지로 해당 파일을 수정

-
다만 master에 server-id를 1을 주었던과는 달리 slave에는 2를 주면 된다.
만약 slave를 더 추가한다면 3, 4.. 이런식으로 숫자를 증가시켜주면 됨.

-
재시작을 꼭 해주자
안해주니 server-id가 설정해달라고 에러가 떴다. 당연한거긴 한데..ㅠㅠ
sudo service mysqld restart-
master db의 정보를 추가해준다.
master db ip, 포트, 유저 이름, 비밀번호, File, Position 값을 추가해준다
CHANGE MASTER TO MASTER_HOST='{master_db_ip}',
MASTER_PORT={master_db_port},
MASTER_USER='{master_db_user_name}',
MASTER_PASSWORD='{master_db_user_password}',
MASTER_LOG_FILE='{master_db_file}',
MASTER_LOG_POS={master_db_position};start slave;//\G 라고 입력하면 이쁘게 출력이 된다
show slave status\G;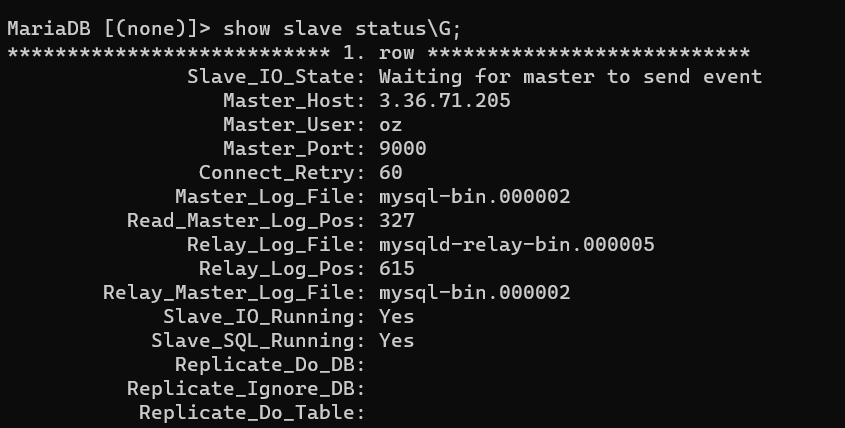
- 각 줄에 대한 의미는 https://myinfrabox.tistory.com/24 여기를 참고하자.
주의 사항
-
처음에 9000으로 포트를 바꿨는데 계속 connection refused가 발생하였다.
찾아보니 https://blog.daum.net/techtip/12415217 9000 포트가 mariadb 설정에 의해서 127.0.0.1에 대해서만 열려있었다.

- 그래서 bind-address를 주석 처리해두었다.

- 이렇게 master와 slave가 연결이 된 시점에서 master의 db에 데이터가 insert되면 slave에도 insert되는 것을 볼 수 있다.
SpringBoot DB Configuration
- 방금까지 한 작업은 각각의 DB 서버에 있는 master와 slave db를 서로 연결시켜준 것이다. 연결을 시켜줌으로써 master db에 insert, update 등의 처리가 발생하면 slave db에도 같이 적용이 되는 것이다.
- 그렇다면 애플리케이션에서는 무슨 작업을 해주어야할까? 사실 db가 연결이 되었다고 해서 우리가 직접 master db 서버에 가서 쿼리문을 실행시키지 않는다. 결국 db에 접근을 하는 것은 애플리케이션에서 하는 것이므로 master와 slave에 맞는 datasource를 선택하고 connection을 하여 쿼리를 처리하도록 코드를 구현해야한다.
- yml에 datasource 설정
- 그렇다면 우선 datasource 설정부터 해보자.
-
예제 코드이므로 간단하게 application.yml에 datasource 정보를 기입한다.
(실제 프로젝트를 진행하면 profile에 따라 설정을 나누기에 더 복잡해질 것이다.)

- DatasourceConfig 설정
// 1
@EnableAutoConfiguration(exclude = DataSourceAutoConfiguration.class)
@Configuration
public class DataSourceConfig {
// 2
private final JpaProperties jpaProperties;
public DataSourceConfig(JpaProperties jpaProperties) {
this.jpaProperties = jpaProperties;
}
// 3
@Bean
public DataSource dataSource() {
return new LazyConnectionDataSourceProxy(routingDataSource());
}
// 4
@Bean
public DataSource routingDataSource() {
DataSource masterDataSource = masterDatasource();
RoutingDataSource routingDataSource = new RoutingDataSource();
routingDataSource.setDefaultTargetDataSource(masterDataSource);
Map<Object, Object> dataSources = Map.of(
"master", masterDataSource,
"slave", slaveDatasource()
);
routingDataSource.setTargetDataSources(dataSources);
return routingDataSource;
}
// 4
@Bean
@ConfigurationProperties(prefix = "datasource.master")
public DataSource masterDatasource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
// 4
@Bean
@ConfigurationProperties(prefix = "datasource.slave")
public DataSource slaveDatasource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
// 5
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
HibernateProperties hibernateProperties = new HibernateProperties();
final Map<String, Object> properties = hibernateProperties.determineHibernateProperties(
jpaProperties.getProperties(), new HibernateSettings()
);
HibernateJpaVendorAdapter hibernateJpaVendorAdapter = new HibernateJpaVendorAdapter();
final EntityManagerFactoryBuilder entityManagerFactoryBuilder = new EntityManagerFactoryBuilder(hibernateJpaVendorAdapter, properties, null);
return entityManagerFactoryBuilder
.dataSource(dataSource())
.packages("com.study.playground.replication")
.build();
}
// 6
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
}// 4
public class RoutingDataSource extends AbstractRoutingDataSource {
private static final Logger log = LoggerFactory.getLogger(RoutingDataSource.class);
@Override
protected Object determineCurrentLookupKey() {
if (TransactionSynchronizationManager.isCurrentTransactionReadOnly()) {
log.info("current db slave");
return "slave";
}
log.info("current db master");
return "master";
}
}- 원래는 한 개의 datasource만 사용하므로 spring.datasource~ 라고 yml에 기입을 하면 spring에서 자동으로 datasource를 설정해준다.
- 하지만 두 개를 사용하며 상황에 따라 master 또는 slave db로 연결이 되어야한다. 그러므로 yml에 기입한 datasource 정보를 이용해 직접 설정을 해주어야 한다.
-
위 코드에서 명시한 번호 순서대로 어떤 역할을 맡고 있는지 명시해보겠다.
- 자동으로 datasource를 설정해주는 DataSourceAutoConfiguration을 해제해준다.
- yml에 명시해 둔 jpa properties 설정이 자동으로 들어온다.
- Spring은 기본적으로 트랜잭션을 시작할 때 쿼리 실행 전에 datasource를 정해놓는다. 따라서 트랜잭션이 시작되면 같은 datasource만을 이용한다. 다만 우리는 쿼리 실행할 때 datasource를 결정해줘야하기 때문에 미리 datasource를 정하지 않도록 프록시 datasource인 LazyConnectionDataSourceProxy를 사용하여 실제 쿼리가 실행될 때 connection을 가져오도록 한 것이다.
- yml에 명시해둔 datasource를 빈으로 등록시킨다. RoutingDataSource의 경우 AbstractRoutingDataSource을 구현한 클래스인데 AbstractRoutingDataSource는 여러 datasource를 등록해 상황에 맞게 원하는 datasource를 사용할 수 있는 추상 클래스라고 생각하면 된다. 이 때 determineCurrentLookupKey() 이라는 메서드를 구현하면 되는데 @Transactional(readOnly=?)에 맞춰서 readOnly가 true면 slave를 false면 master를 key로 반환하여 등록된 datasources map에서 value를 반환하게 된다.
- EntitiyManagerFactory 설정이다. 원래는 datasource가 자동연결되면서 JPA에 대한 설정도 되지만 우리는 직접 해야한다. 이 때 Hibernate 설정도 해주게 되는데 앞서 말했듯이 직접 설정을 하다보니 기본적으로 DataSourceAutoConfiguration에서 해주는 네이밍 전략과 같은 설정도 해주어야한다. yml에 같이 명시를 해주어도 되지만 위의 예제와 같이 HibernateProperties를 만들고 determineHibernateProperties() 메서드를 실행하면 기본 설정 + yml에 명시해준 jpa 설정이 같이 합쳐진 properties가 만들어지고 이를 사용해주면 된다.
- 마찬가지로 TransactionManager도 직접 설정해준다.
Replication Test
- 테스트 코드를 통해 insert할 때 master db로 연결하고 select할 때 slave db로 연결되는지 확인해보자.
- @Transactional의 readOnly 설정에 의해 datasource를 고르는 것으로 알고 Controller와 Service를 다 만들어서 인수테스트로 진행할까 했는데 신기하게도 Repository의 save와 findById 만으로도 readOnly 분기를 탈 수 있다.
- 정확히는 잘 모르겠지만 논리적으로 봤을 때 하나의 트랜잭션에서 하나의 find를 사용하면 당연히 readOnly가 true이니 가능한게 아닌가 싶기도 하다.
@SpringBootTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE) //datasource 자동연결을 막아준다.
public class ReplicationTest {
@Autowired
private UserRepository userRepository;
private User user;
@BeforeEach
void setUp() {
user = new User("oz", 500);
}
@Test
@DisplayName("save를 하면 master db에 데이터를 insert 한다.")
void insert() {
// given
Logger logger = (Logger) LoggerFactory.getLogger(RoutingDataSource.class);
ListAppender<ILoggingEvent> listAppender = new ListAppender<>();
logger.addAppender(listAppender);
listAppender.start();
// when
userRepository.save(user);
// then
final List<ILoggingEvent> list = listAppender.list;
assertThat(list).hasSize(1);
assertThat(list)
.extracting(ILoggingEvent::getFormattedMessage)
.anyMatch(log -> log.equals("current db master"));
}
@Test
@DisplayName("find를 하면 slave db의 데이터를 select 한다.")
void find() {
// given
userRepository.save(user);
Logger logger = (Logger) LoggerFactory.getLogger(RoutingDataSource.class);
ListAppender<ILoggingEvent> listAppender = new ListAppender<>();
logger.addAppender(listAppender);
listAppender.start();
// when
User findUser = userRepository.findById(user.getId())
.orElseThrow(IllegalStateException::new);
// then
final List<ILoggingEvent> list = listAppender.list;
assertThat(list).hasSize(1);
assertThat(list)
.extracting(ILoggingEvent::getFormattedMessage)
.anyMatch(log -> log.equals("current db slave"));
assertThat(findUser).isEqualTo(user);
}
}- RoutingDataSource에서 readOnly 인지에 따라 master, slave db를 사용하기 전에 로그를 남기도록 하였고 이 로그를 이용해 테스트를 진행했다.
왜 Replication을 적용할까?
- 프로젝트 규모가 커짐에 따라 DB를 사용할 일은 더 많아질 것이다. 이 때 DB에서 고민할 것들이 몇 가지가 있을 것이다.
- 데이터의 백업
- 부하 분산
Replication을 통해 이를 모두 수행할 수 있다.
- master db로 데이터 쓰기 및 업데이트 작업을 하면 연결된 slave db들 모두 쓰기 및 업데이트 작업이 일어나므로 데이터의 백업을 할 수 있다.
- readOnly 속성을 통해 쓰기 및 업데이트 작업은 master db에서 읽기 작업은 slave db 중 하나에서 행함으로써 부하 분산을 할 수 있다.
마무리
- 보고 또 보고 프로젝트에서 Replication을 적용시켰기에 학습하기 위해 한번 따라해보았다.
- Replication을 적용하면 여러 장점이 있지만 서버를 만들거나 적용하는데 쏟는 시간 또한 다 비용이기에 도입할 때는 충분히 고려해야할 것 같다.
- master와 slave 사이의 데이터가 불일치할 수 있는 문제 또한 생각해봐야할 것 같다.